定义
图(Graph)是图形结构的简称。
G = (V, E)
V称为顶点集(Vertices set),E称为边集(Edges set)。E的元素是一个二元组数对,用(x,y)表示,其中x,y∈V。
其中V是非空的顶点集合,即V = {Vi|0≤i≤n-1,n≥1, Vi$\in$VertexType},其中VertexType表示任何类型,n为顶点数;
E是V上二元关系的集合。
V(G1) = {0,1,2,3,4,5,}
E(G1) = {(0,1),(0,2),(0,3),(0,4),(1,4),(2,4),(3,5),(4,5)}
V(G2) = {0,1,2,3,4}
E(G2) = {<0,1>,<0,2>,<1,2>,<1,4>,<2,1>,<2,3>,<4,3>}
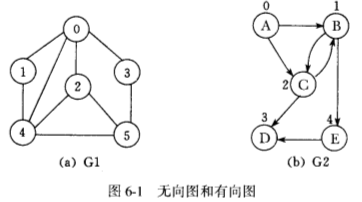
G1为无向图(undirected graph),图中每个元素为一个无序二元组 (u,v),称作无向边 (Undirected edge),简称**边 (Edge),其中 u,v∈V。设 e=(u,v),则 u,v 称为 e 的端点 (End-vertex)**。
G2为有向图(directed graph),每一个元素为一个 (有序) 二元组 (u,v),有时也写作 u→v,称作有向边 (Directed edge) 或弧 (Arc),在不引起混淆的情况下也可以称作边。设 e=u→v,则此时 u 称为 e 的起点 (Origin),v 称为 e 的终点 (Terminus),起点和终点也称为 e 的端点。
对于 V 中的每个元素,我们称其为**顶点 (Vertex)或节点 (Node)**,简称点 (Vertex),顶点的集合称为点集 (Vertex set),边的集合称为边集 (Edge set)。
图 G 的点集和边集可以表示为 V(G) 和 E(G),在不引起混淆的情况下,也能表示成 V,E。图 G 的点数 |V(G)| 也被称作图 G 的阶 (Order)。
基本术语
顶点的度、入度、出度
度:顶点v的度(Degree)是和v相关联的边的数目,记为TD(v)。
对于有向图G=(V,{E}),如果弧∈E,则称顶点v邻接到顶点v’,顶点v’邻接自顶点v。弧和顶点v,v’相关联。以顶点v为
头弧的数目称为v的入度(InDegree),记为ID(v);以v为尾的弧的数目称为v的出度(OutDegree),记为OD(v);
顶点v的度为TD(v)=ID(v)+OD(v)。
完全图、稠密图、稀疏图
完全图:每个顶点都与其他顶点相邻接的图。
有很少条边或弧(边的条数|E|远小于|V|²)的图称为稀疏图(sparse graph),反之边的条数|E|接近|V|²,称为稠密图(dense graph)。
路径和回路
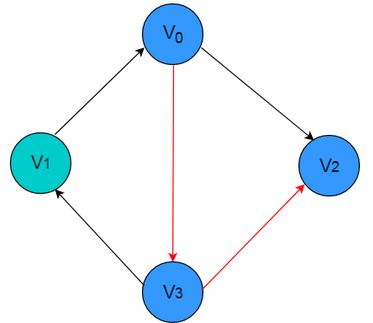
依次遍历顶点序列之间的边所形成的轨迹。下图中依次访问顶点 V0 、V3 和 V2 ,则构成一条路径。
连通和连通分量
在无向图 G 中,如果从顶点 v 到顶点 v’ 有路径,则称 v 和 v’ 是连通的。 如果对于图中任意两个顶点 vi 、vj ∈E, vi,和vj都是连通的,则称 G 是连通图,否则图为非连通图。
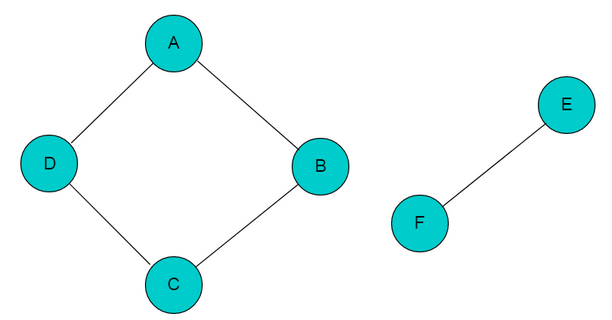
非连通图:
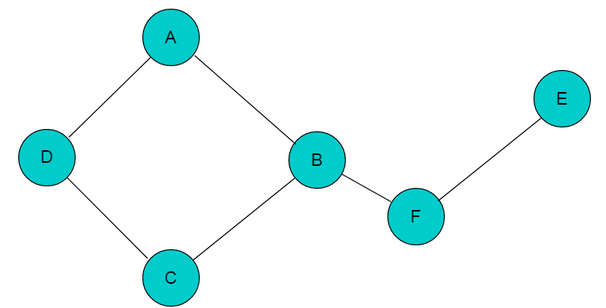
连通图:
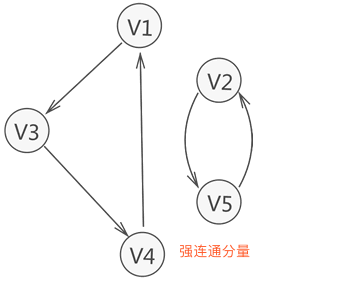
强连通图和强连通分量
在有向图G中,如果两个顶点vi,vj间(vi>vj)有一条从vi到vj的有向路径,同时还有一条从vj到vi的有向路径,则称两个顶点强连通(strongly connected)。如果有向图G的每两个顶点都强连通,称G是一个强连通图。有向图的极大强连通子图,称为强连通分量(strongly connected components)。
网
“权”指边上面的信息,一般为数字。
每条边上都带有权的图叫做网。
存储结构
1 | ADT 图(Graph) |
邻接矩阵(Adjacency Matrix)
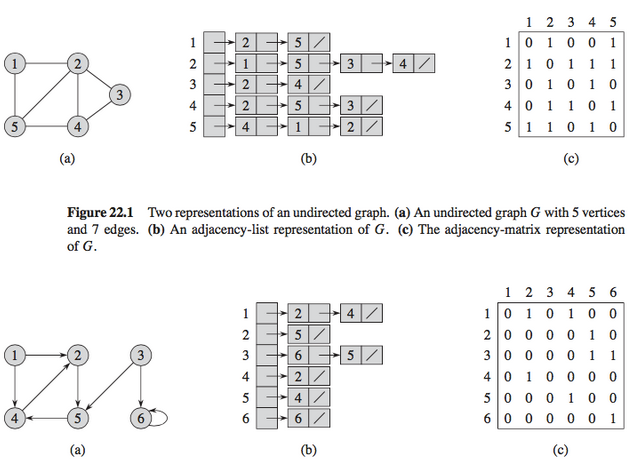
用两个数组来表示图。一个一维的数组存储图中顶点信息,一个二维数组(称为邻接矩阵)存储图中的边或弧的信息。
对于 n 个点,构造一个 n * n 的矩阵,如果有从点 i 到点 j 的边,就将矩阵的位置 matrix[i][j] 置为 1。
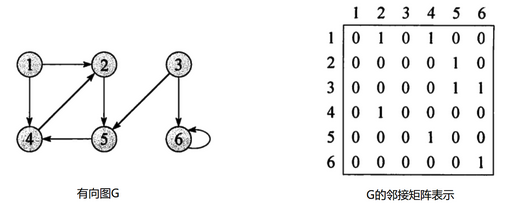
通常会将图 G 中的结点编为1,2,…,|V| (这种编号可以是任意的),然后使用一个 |V| ×|V| 的矩阵 A=(aij) 表示,该矩阵满足以下条件:

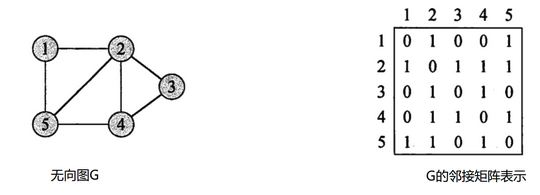
可以看出邻接矩阵是在无向图的表示中是转置矩阵,而在有向图中则不是。
对于带权图来说,可以将aij
用来存储权值,如果两结点无连接,用0或无穷表示:

无向图邻接矩阵的特征
- 无向图的邻接矩阵对称且唯一。
- 有向图的邻接矩阵的第 i 行非零元素个数为第 i 个顶点的出度;第 j 列非零元素个数为第 j 个顶点的入度。
- 可快速判断两结点间是否有边。
- A[i][j] = 1代表顶点i与顶点j邻接,A[i][j] = 0代表顶点i与顶点j不邻接。
- 顶点与自身之间并未邻接关系,因此边数组的对角线上的元素均为0。
- 顶点的度即为顶点所在的行或者列1的数目。
有向图邻接矩阵的特征
- 顶点数组长度为图的顶点数目n。边数组为n X n的二维数组。
- 边数组中,数组元素为1,即A[i][j] = 1,代表第i个顶点与第j个顶点邻接,且i为尾,j为头。 A[i][j] = 0代表顶点与顶点不邻接。
- 在有向图中,由于边存在方向性,因此数组不一定为对称数组。
- 对角线上元素为0。
- 第i行中,1的数目代表第i个顶点的出度。例如:顶点V1的出度为2,则顶点V1所在行的1的数目为2。
- 第j列中,1的数目代表第j个顶点的入度。例如:V3的入度为1,则V3所在列中1的数目为1。
邻接表(adjacency list)
邻接链表(adjacency list)由图中的每一个结点及其相邻结点生成以该结点为头结点的一组链表。
当处理稀疏图时,相对于邻接矩阵,邻接链表无需一次就分配那么大的空间,而是在遍历图的过程中一点一点地分配,它是一种顺序分配和链式分配相结合的存储结构。如这个表头结点所对应的顶点存在相邻顶点,则把相邻顶点依次存放于表头结点所指向的单向链表中。
虽然邻接链表是一种非常节约空间的结构,但在无向图中用邻接链表表示也会出现数据冗余。这是因为表头结点A所指链表中存在一个指向C的表结点的同时,表头结点C所指链表也会存在一个指向A的表结点。
邻接表存储方法是一种数组存储和链式存储相结合的存储方法。在邻接表中,对图中的每个顶点建立一个单链表,第 i 个单链表中的结点依附于顶点 Vi 的边(对有向图是以顶点Vi为尾的弧)。链表中的节点称为表节点,共有 3个域,具体结构见下图:

表结点由三个域组成,adjvex存储与Vi邻接的点在图中的位置,nextarc存储下一条边或弧的结点,info存储与边或弧相关的信息如权值。
除表结点外,需要在数组中存储头结点,头结点由两个域组成,分别指向链表中第一个顶点和存储Vi的名或其他信息。具体结构如下图:

其中,data域中存储顶点相关信息,firstarc指向链表的第一个节点。
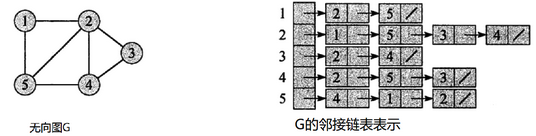
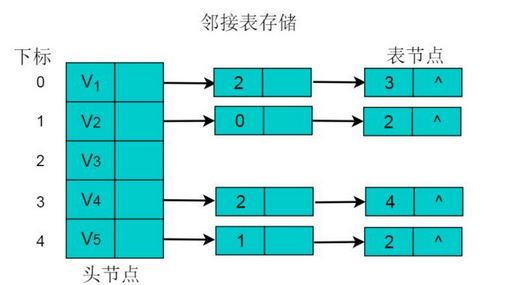
无向图采用邻接表方式存储
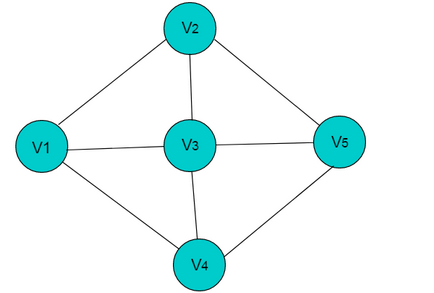
采用邻接表方式存储图 6.1 中的无向图,绘图过程中忽略边节点的info信息,头结点中的 data 域存储顶点名称。以V1顶点为例,V1顶点的邻接顶点为V2、V3、V4,则可以创建3个表节点,表节点中adjvex分别存储V2、V3、V4的索引1、2、3,按照此方式,得到的邻接表为:
特征
- 数组中头节点的数目为图的顶点数目。
- 链表的长度即为顶点的度。例如:V1顶点的度为3,则以V1为头节点的链表中表节点的数目为3。
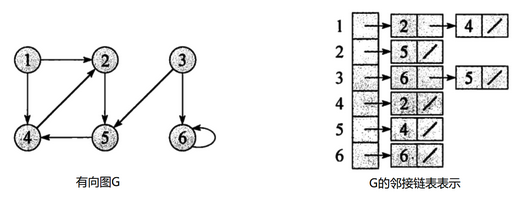
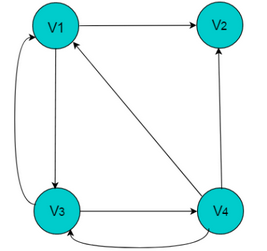
有向图采用邻接链表方式存储
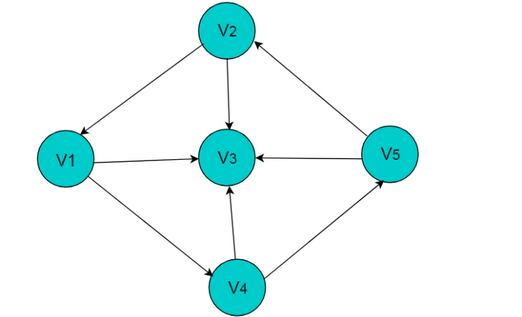
采用邻接表方式存储图6.3中的有向图,绘图过程中忽略边节点的info信息,头结点中的data域存储顶点名称。以V1顶点为例,V1顶点的邻接顶点为V2、V3、V4,但是以V1顶点为尾的边只有两条,即和因此,创建2个表节点。表节点中adjvex分别存储V3、V4的索引2、3,按照此方式,得到的邻接表为:
特征
- 数组中表节点的数目为图的顶点数目。
- 链表的长度即为顶点的出度。例如V1的出度为2,V1为头节点的链表中,表节点的数目为2。
- 顶点Vi的入度为邻接表中所有adjvex值域为i的表结点数目。例如:顶点V3的入度为4,则链表中所有adjvex值域为2的表结点数目为4。
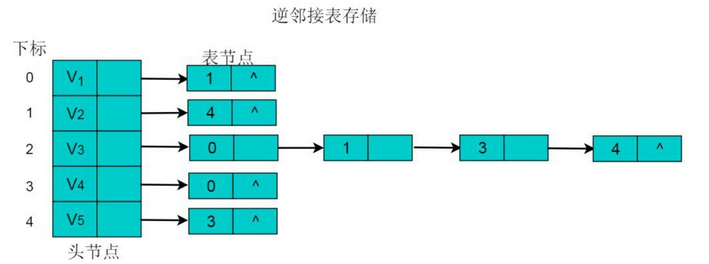
逆邻接表
在邻接表中,可以轻易的得出顶点的出度,但是想要得到顶点的入度,则需要遍历整个链表。为了便于确定顶点的入度,可以建立有向图的逆邻接表。逆邻接表的建立与邻接表相反。
十字链表
对于有向图而言,邻接链表的缺陷是要查询某个顶点的入度时需要遍历整个链表,而逆邻接链表在查询某个顶点的出度时要遍历整个链表。为了解决这些问题,十字链表将邻接链表和逆邻接链表综合了起来,而得到的一种十字链表。在十字链表中,每一条边对应一种边节点,每一个顶点对应为顶点节点。
顶点结点
顶点节点即为头节点,由3个域构成,具体形式如下:

其中,data域存储与顶点相关的信息,firstin和firstout分别指向以此顶点为头或尾的第一个边节点。
边结点
在边节点为链表节点,共有5个域,具体形式如下:

其中,尾域tailvex和头域headvex分别指向尾和头的顶点在图中的位置。链域hlink指向头相同的下一条边,链域tlink指向尾相同的下一条边。info 存储此条边的相关信息。
例如:
采用十字链表的方式存储图的有向图,绘图过程忽略边节点中的info信息,表头节点中的data域存储顶点名称。以V1顶点为例,顶点节点的data域存储V1顶点名,firstin存储以V1顶点为头第一个边节点,以V1顶点为头边为,firstout存储以以V1顶点为尾第一个边节点,对应边为。按照此规则,得到的十字链表存储为:
邻接多重表
对于无向图而言,其每条边在邻接链表中都需要两个结点来表示,而邻接多重表正是对其进行优化,让同一条边只用一个结点表示即可。邻接多重表仿照了十字链表的思想,对邻接链表的边表结点进行了改进。

其中,ivex和jvex是指某条边依附的两个顶点在顶点表中的下标。 ilink指向依附顶点ivex的下一条边,jlink指向依附顶点jvex的下一条边。info存储边的相关信息。
重新定义的顶点结构如下图:

其中,data存储顶点的相关信息,firstedge指向第一条依附于该顶点的边。
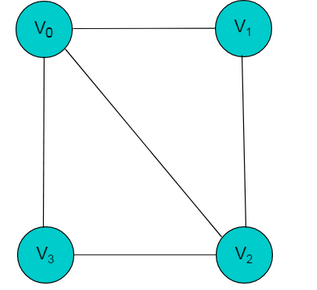
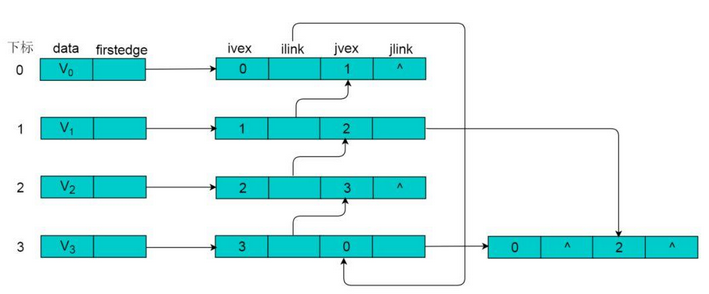
所示的无向图,采用邻接多重表存储,以 V0 为例,顶点节点的data域存储V0名称,firstedge 指向(V0 , V1)边,边节点中的ilink指向依附V0顶点的下一条边(V0 , V3),jlink指向依附V1顶点的下一条边(V1 , V2),按照此方式建立邻接多重表:
关联矩阵
邻接矩阵和邻接链表都是用来表示图中各个点和每个点之间的关系,而关联矩阵(incidence matrix)即用一个矩阵来表示各个点和每条边之间的关系。
设无向图 G=(V,E),其中顶点集 V=v1,v2,⋯,vn, 边集 E=e1,e2,⋯,em,用 aij 表示顶点vi与边ej 关联的次数,可能取值为0, 1, 2, ….,我们称所得矩阵A=A(G)=(aij)n×m为图 G 的关联矩阵。
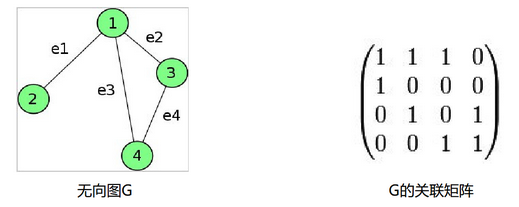
对于关联矩阵第一行1 1 1 0,表示点v1和各边的关系。如图所示,v1和e1,e2,e3相连,和e4未连,故关联矩阵的值为1 1 1 0. 下面各行为点v2,v3,v4
和各边的关联,以此类推。因此每一行值的总和为该点的度。
对于有向图,若bij=1,表示边j离开点i。 若 bij= -1, 表示边j进入点i。 若 bij = 0,表示边j和点i不相关联。